
Let me start by stating two facts – facts that I will substantiate if you continue to the end.
Fact #1: Windows suffers from severe write inefficiencies that dampen overall performance. The holy grail question as to how severe is answered below.
Fact #2: Windows is still Windows whether running in the cloud, on hyperconverged systems, all-flash storage, or all three. Before you jump to the real-world examples below, let me first explain why.
No matter where you run Windows and no matter what kind of storage environment you run Windows on, Windows still penalizes optimal performance due to severe write inefficiencies in the hand-off of data to storage. What happens is that files are always broken down to be much smaller than they need to be. Since each piece means a dedicated I/O operation to process as a write or read, this means an enormous amount of noisy, unnecessary I/O traffic is chewing up precious IOPS, eroding throughput, and causing everything to run slower no matter how many IOPS are at your disposal.
How much slower?
Now that the latest version of our I/O performance acceleration software is being run across tens of thousands of servers and hundreds of thousands of PCs, we can empirically point out that no matter what kind of environment Windows is running on, there is always 30-40% of I/O traffic that is nothing but mere noise, stealing resources and robbing optimal performance.
Yes, there are edge cases in which the inefficiency is as little as 10% but also cases where the inefficiency is upwards of 70%. That being said, the median range is solidly in the 30-40% range and it has absolutely nothing to do with the backend media whether spindle, flash, hybrid, hyperconverged, cloud, or local storage.
Even if you’re running Windows on an all-flash hyperconverged system, SAN, or cloud environment with low latency and high IOPS, 30-40% more IOPS will always be required for any given workload, unless the I/O profile is being addressed by our I/O transformation software to ensure large, clean, contiguous writes and reads. This adds up to unnecessarily giving away 30-40% of the IOPS you paid for while slowing the completion of every job and query by the same amount.
So what’s going on here? Why is this happening and how?
First of all, the behavior of Windows when it comes to processing write and read input/output (I/O) operations is identical despite the storage backend whether local or network media, spindles or flash. This is because Windows only ever sees a virtual disk – the logical disk within the file system itself. The OS is abstracted from the physical layer entirely. Windows doesn’t know and doesn’t care if the underlying storage is a local disk or SSD, an array full of SSDs, hyperconverged, or cloud. In the mind of the OS, the logical disk IS the physical disk when, in fact, it’s just a reference architecture. In the case of enterprise storage, the underlying storage controllers manage where the data physically lives. However, no storage device can dictate to Windows how to write (and subsequently read) in the most efficient manner possible.
This is why many enterprise storage controllers have their own proprietary algorithms to “clean up” the mess Windows gives them by either buffering or coalescing files on a dedicated SSD or NVRAM tier or physically moving pieces of the same file to line up sequentially. This does nothing for the first penalized write nor several penalized reads after as the algorithm first needs to identify a continued pattern before moving blocks. As much as storage controller optimization helps, it’s a far cry from an actual solution because it doesn’t solve the source of the larger root cause problem. Even with backend storage controller optimizations, Windows will still make the underlying server to storage architecture execute many more I/O operations than are required to write and subsequently read a file, and every extra I/O required takes a measure of time in the same way that four partially loaded dump trucks will take longer to deliver the full load versus one fully loaded dump truck.
It bears repeating – no storage device can dictate to Windows how to best write and read files for the healthiest I/O profile that delivers optimum performance, because only Windows controls how files are written to the logical disk. And that singular action is what determines the I/O density (or lack of) from server to storage.
The reason this is occurring is because there are no APIs that exist between the Windows OS and underlying storage system whereby free space at the logical layer can be intelligently synced and consolidated with the physical layer without change block movement that would otherwise wear out SSDs and trigger copy-on-write activity that would blow up storage services like replication, thin provisioning, and more.
This means Windows has no choice but to choose the next available allocation at the logical disk layer within the file system itself instead of choosing the BEST allocation to write and subsequently read a file.
“Death by a thousand cuts”
The problem is that the next available allocation is only ever the right size on day 1 on a freshly formatted NTFS volume. But as time goes on and files are written and erased and re-written and extended and many temporary files are quickly created and erased, that means the next available space is never the right size. So, when Windows is trying to write a 1MB file but the next available allocation at the logical disk layer is 4K, it will fill that 4K, split the file, generate another I/O operation, look for the next available allocation, fill, split, and rinse and repeat until the file is fully written, and your I/O profile is cluttered with split I/Os.
The result is an I/O degradation of excessively small writes and reads that penalizes performance with a “death by a thousand cuts” scenario.
Addressing the root cause problem
It’s for this reason, over 2,500 small, mid-sized, and large enterprises have deployed our I/O performance acceleration software to eliminate all that noisy I/O robbing performance by addressing the root cause problem. Since Condusiv’s DymaxIO software sits at the storage driver level, our purview is able to supply patented intelligence to the Windows OS, enabling it to choose the BEST allocation for any file instead of the next available, which is never the right size. This ensures the healthiest I/O profile possible for maximum storage performance on every write and read.
Above and beyond that benefit, our DRAM read caching engine (the same engine OEM’d by 9 of the top 10 PC manufacturers), eliminates hot reads from traversing the full stack from storage by serving it straight from idle, available DRAM. Customers who add anywhere to 4GB-16GB of memory to key systems with a read bias to get more from that engine, will offload 50-80% of all reads from storage, saving even more precious storage IOPS by serving from DRAM which is 15X faster than SSD. Those who need the most performance possible or simply need to free up more storage IOPS will max our 128GB threshold and offload 90-99% of reads from storage!
Windows performance in the real world
Let’s look at some real-world examples from customers.
Here is VDI in AWS shared by Curt Hapner (CIO, Altenloh Brinck & Co.). 63% of read traffic and 33% of write I/O operations are being offloaded from underlying storage. He was getting sluggish VDI performance, so he bumped up memory slightly on all instances to get more power from our software and the sluggishness disappeared.
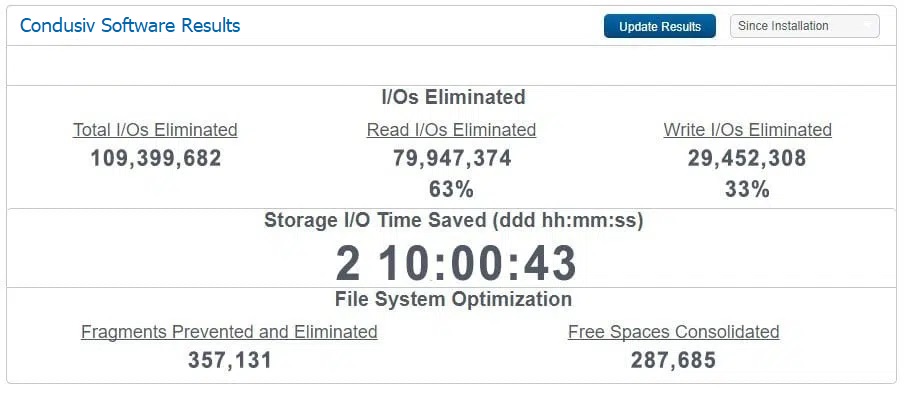
AWS sluggishness disappeared with Condusiv
Here is an Epicor ERP with SQL backend in AWS from Altenloh Brinck & Co. 39% of reads are being eliminated along with 44% of writes to boost the performance and efficiency of their most mission critical system.
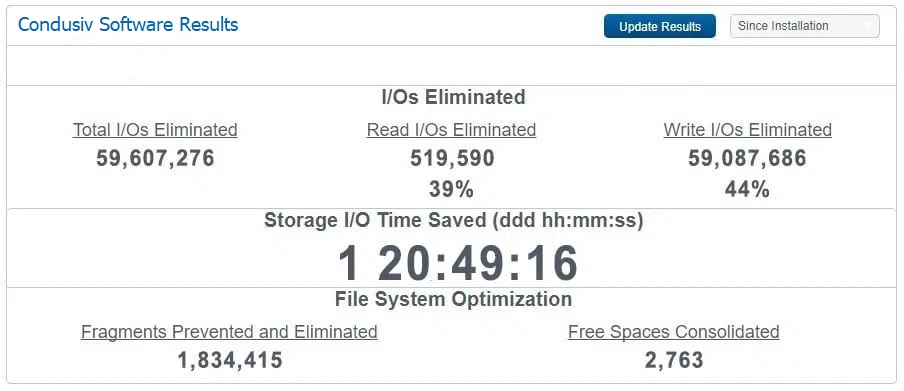
Boosted performance and efficiency on an Epicor ERP with SQL backend in AWS
Here’s from one of the largest federal branches in Washington running Windows servers on an all-flash Nutanix. 45% of reads and 38% of write traffic are being offloaded.
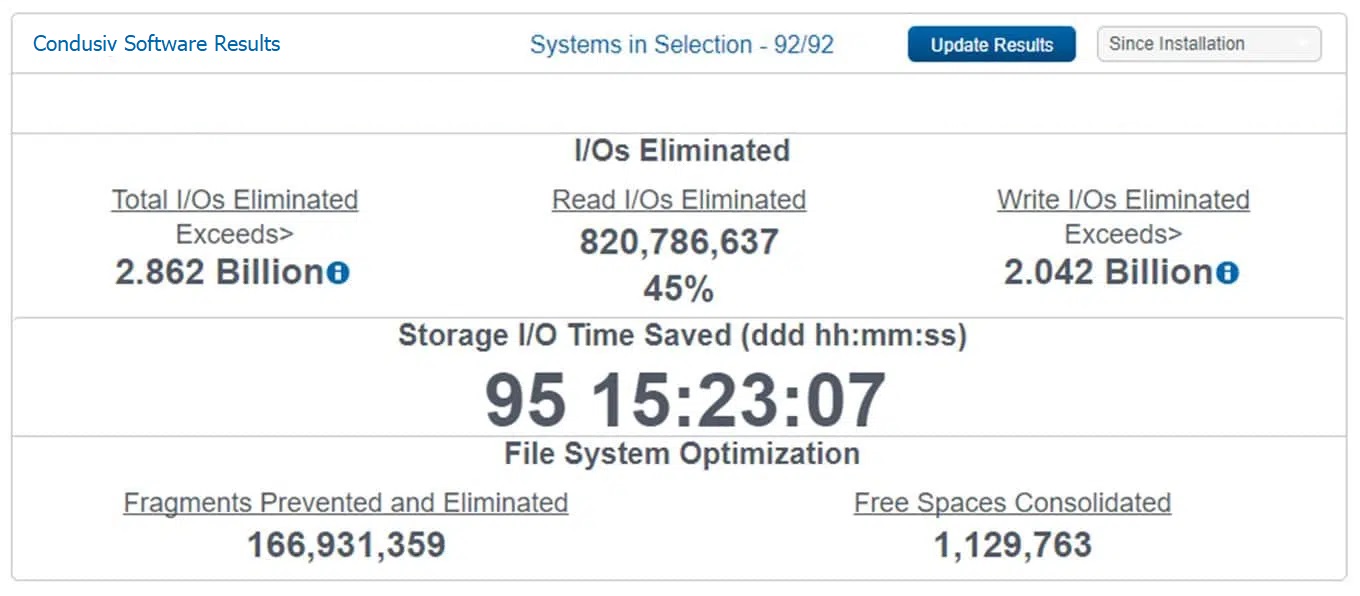
Massive performance increases on Windows servers on an all-flash Nutanix
Here is a spreadsheet compilation of different systems from one of the largest hospitality and event companies in Europe who run their workloads in Azure. The extraction of the dashboard data into the CSV shows not just the percentage of read and write traffic offloaded from storage but how much I/O capacity our software is handing back to their Azure instances.
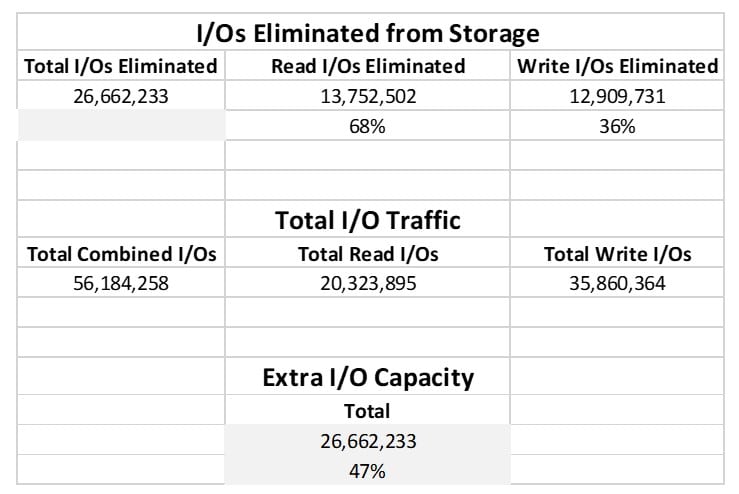
Azure performance increases with I/O performance acceleration software
Condusiv’s Chief Architect
To illustrate we use the software here at Condusiv on our own systems, this dashboard screenshot is from our own Chief Architect (Rick Cadruvi), who uses DymaxIO on his SSD-powered PC.
As you can see, 36% of reads are offloaded from his local SSD while 33% of write operations have been saved by displacing small, fractured files with large, clean contiguous files. Not only is that extending the life of his SSD by reducing write amplification, but he has saved over 8 days of I/O time in the last several months.
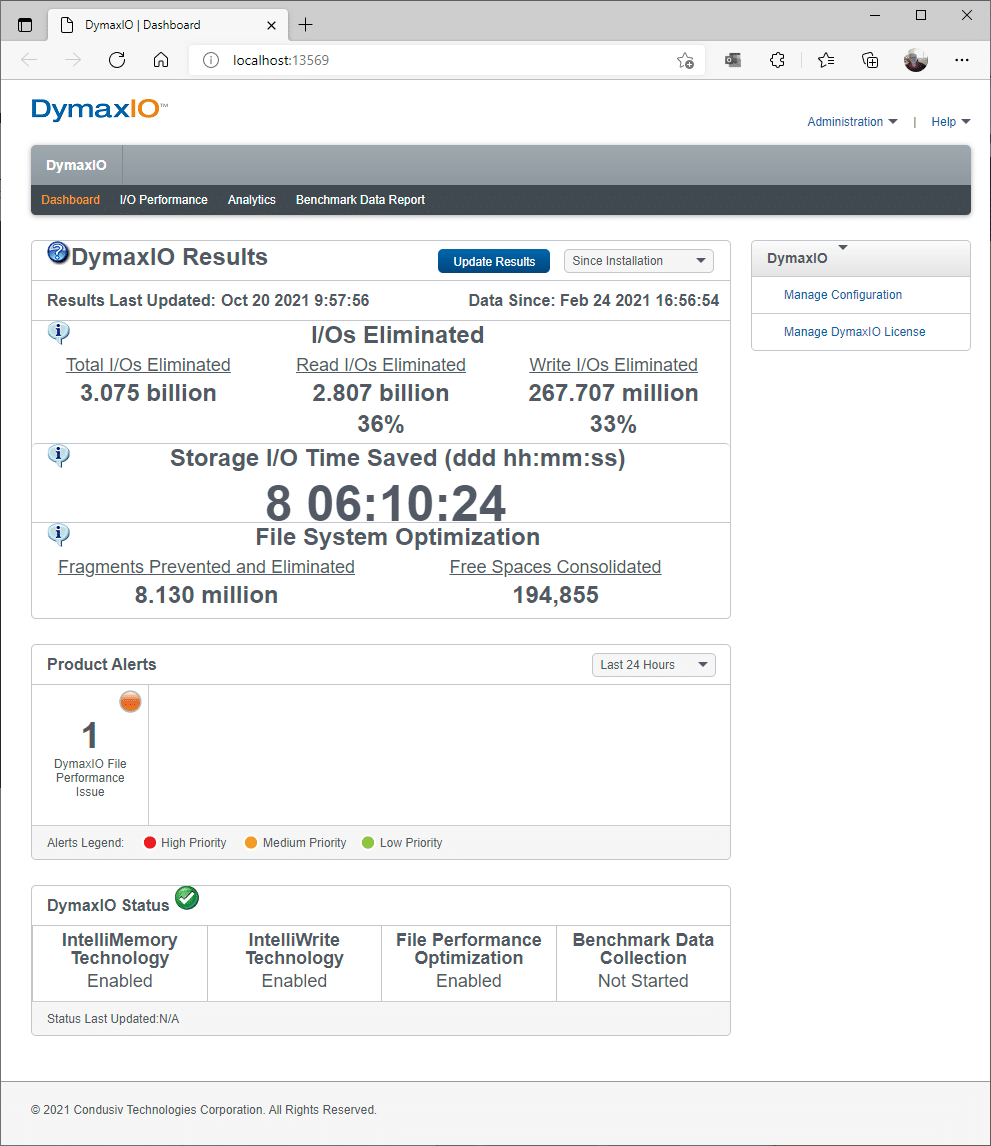
DymaxIO on Chief Architect’s SSD-powered PC
Windows on All-Flash Storage Systems
Finally, regarding all-flash SAN storage systems, the full data is in this case study with the University of Illinois who used Condusiv I/O performance acceleration software to more than double the performance of SQL and Oracle sitting on their all-flash arrays.
See in your own environment
V-locity, Diskeeper, and SSDkeeper are now DymaxIO.
You can download a free 30-day trial of new DymaxIO I/O performance acceleration software.
For best results, bump up memory on key systems if you can and make sure to install the software on all the VMs on the same host. If you have more than 10 VMs, you may want to Contact Us for SE assistance in spinning up our centralized management console to push everything at once – a 20-min exercise with no reboot required.
See for more than 20 case studies on how our I/O performance acceleration software doubled the performance of mission critical applications like MS-SQL for customers of various environments.
Ready to just get going boosting Windows performance with a subscription now, you can purchase online.
Originally published June 2018. Updated 2019, 2020, July 2021, October 2021, August 2022.




Hello
All the information given above! you may understand? or not, you do not need to! was my first encounter, interesting yes, for a reasonable cost give it a go. I did and was amazed at my computers performance increase in a reasonable period of time. Over the years with new computers and operating systems, I have always included Diskeeper as a computer aid to performance! I do not need to know how Diskeeper do it? I only know and remember the difference before and after installation of the Disc keepers software.
This is why you install Diskeeper! your computer runs so much slicker the additional cost means nothing compared to the benefits you get when running a windows based operating system. I have been running Diskeeper for more than a few years and benefited by its constant evolution over the years, I.O. reduction turns your computer into a sport car highly recommended.
Hi James,
Thanks for your ongoing support! Have a great day!
Kellie