Since the news broke on the Intel CPU security flaw, we have fielded customer concerns about the potential impact to our software and worries of increased contention for CPU cycles if less CPU power1 is available after the patches issued by affected vendors.
Let us first simply state there is no overhead concern regarding Condusiv software related to software contention for fewer CPU cycles post-patch. If any user has concerns about CPU overhead from Condusiv software, then it is important that we communicate how Condusiv software is architected to use CPU resources in the first place (explained below) such that it is not an issue.
Google reported this issue to Intel, AMD and ARM on Jun 1, 2017. The issue became public Jan 3, 2018. The issue affects most Intel CPUs dating back to 1995. Most OSes released a patch this week to mitigate the risk. Also, firmware updates are expected soon. A report about this flaw from the Google Project Zero team can be found at:
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
Before discussing the basic vulnerabilities and any impact the security flaw or patch has or doesn’t have on V-locity®/SSDkeeper®/Diskeeper® (or how our software actually proves beneficial), let me first address the performance hits anticipated due to patches in OSes and/or firmware. While the details are being tightly held, probably to keep hackers from being able to exploit the vulnerabilities, the consensus seems to be that the fixes in the OSes (Windows Linux, etc.) will have a potential of reducing performance by 5%-30%1. A lot of this depends on how the system is being used. For most dedicated systems/applications the consensus appears to be that the affect will be negligible. That is likely due to the fact that most of those systems already have excess compute capability, so the user just won’t experience a noticeable slowdown. Also, they aren’t doing lots of things concurrently.
The real issue comes up for servers where there are multiple accessors/applications hitting on the server. They will experience the greatest degradation as they will likely have the most number of overlapping data access. The following article indicates that the biggest performance hits will happen on reads from storage and on SSDs.
https://www.pcworld.com/article/3245606/security/intel-x86-cpu-kernel-bug-faq-how-it-affects-pc-mac.html
So what about V-locity/Diskeeper/SSDkeeper?
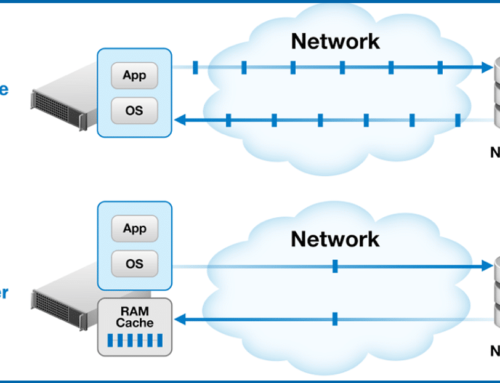
As previously mentioned, we can state that there is not increased CPU contention or negative overhead impact by Condusiv software. Condusiv background operations run at low priority, which means only otherwise idle and available CPU cycles are used. This means that despite whatever CPU horsepower is available (a lot or little), Condusiv software is unobtrusive on server performance because its patented Invisitasking® technology only uses free CPU cycles. If computing is ever completely bound by other tasks, Condusiv software sits idle so there is NO negative intrusion or impact on server resources. The same can be said about our patented DRAM caching engine (IntelliMemory®) as it only uses memory that is otherwise idle and not being used – zero contention for resources.
However, if storage reads slow down due to the fix (per the PC World article), our software will certainly overcome a significant amount of the lost performance since eliminating I/O traffic in the first place is what our software is designed to do. Telemetry data across thousands of systems demonstrates our software eliminates 30-40% of noisy and completely unnecessary I/O traffic on typically configured systems2. In fact, those who add just a little more DRAM on important systems to better leverage the tier-0 caching strategy, see a 50% or more reduction, which pushes them into the 2X faster gains and higher.
Those organizations who are concerned about loss of read performance from their SSDs due to the chip fixes and patches need only do one thing to mitigate that concern – simply allocate more DRAM to important systems. Our software will pick up the additional available memory to enhance your tier-0 caching layer. For every 2GB of memory added, we typically see a conservative 25% of read traffic offloaded from storage. That figure is often times 35-40% and even as high as 50% depending on the workload. Since our behavioral analytics engine sits at the application layer, we are able to cache very effectively with very little cache churn. And since DRAM is 15X faster than SSD, that means only a small amount of capacity can drive very big gains. Simply monitor the in-product dashboard to watch your cache hit rates rise with additional capacity.
Regarding the vulnerabilities themselves, for a very long time, memory in the CPU chip itself has been a LOT faster than system memory (DRAM). As a result, chip manufacturers have done several things to help take advantage of CPU speed increases. For the purpose of this paper, I will be discussing the following 2 approaches that were used to improve performance:
1. Speculative execution
2. CPU memory cache
These mechanisms to improve performance opened up the security vulnerabilities being labeled “Spectre” and “Meltdown”.
Speculative execution is a technology whereby the CPU prefetches machine instructions and data from system memory (typically DRAM) for the purpose of predicting likely code execution paths. The CPU can pre-execute various potential code paths. This means that by the time the actual code execution path is determined, it has often already been executed. Think of this like coming to a fork in the road as you are driving. What if your car had already gone down both possible directions before you even made a decision as to which one you wanted to take? By the time you decided which path to take, your car would have already been significantly further on the way regardless of which path you ultimately chose.
Of course, in our world, we can’t be at two places at one time, so that can’t happen. However, a modern CPU chip has lots of unused execution cycles due to synchronization, fetching data from DRAM, etc. These “wait states” present an opportunity to do other things. One thing is to figure out likely code that could be executed and pre-execute it. Even if that code path wasn’t ultimately taken, all that happened is that execution cycles that would otherwise have been wasted, just tried those paths even though they didn’t need to be tried. And with modern chips, they can execute lots of these speculative code paths.
Worst case – No harm No foul, right? Not quite. Because the code, and more importantly the DRAM data needed for that code, got fetched it is in the CPU and potentially available to software. And, the data from DRAM got fetched without checking if it was legal for this program to read it. If the guess was correct, your system increased performance a LOT! BUT, since memory (that may not have had legal access based on memory protection) was pre-fetched, a very clever program could take advantage of this. Google was able to create a proof of concept for this flaw. This is the “Spectre” case.
Before you panic about getting hacked, realize that to effectively find really useful information would require extreme knowledge of the CPU chip and the data in memory you would be interested in. Google estimates that an attack on a system with 64GB of RAM would require a software setup cycle of 10-30 minutes. Essentially, a hacker may be able to read around 1,500 bytes per second – a very small amount of memory. The hacker would have to attack specific applications for this to be effective.
As the number of transistors in a chip grew dramatically, it became possible to create VERY large memory caches on the CPU itself. Referencing memory from the CPU cache is MUCH faster than accessing the data from the main system memory (DRAM). The “Meltdown” flaw proof of concept was able to access this data directly without requiring the software to have elevated privileges.
Again, before getting too excited, it is important to think through what memory is in the CPU cache. To start with, current chips typically max out around 8MB of cache on chip. Depending on the type of cache, this is essentially actively used memory. This is NOT just large swaths of DRAM. Of course, the exploit fools the chip caching algorithms to think that the memory the attack wants to read is being actively used. According to Google, it takes more than 100 CPU cycles to cause un-cached data to become cached. And that is in CPU word size chunks – typically 8 bytes.
So what about V-locity/Diskeeper/SSDkeeper?
Our software runs such that we are no more or less vulnerable than any other application/software component. Data in the NTFS File System Cache and in SQL Server’s cache are just as vulnerable to being read as data in our IntelliMemory cache. The same holds true for Oracle or any other software that caches data in DRAM. And, your typical anti-virus has to analyze file data, so it too may have data in memory that could be read from various data files. However, as the chip flaws are fixed, our I/O reduction software provides the advantage of making up for lost performance, and more.
1 https://www.theregister.co.uk/2018/01/02/intel_cpu_design_flaw/
2 https://condusiv.com/new-dashboard-finally-answers-the-big-question/